Understanding Business Intelligence and Power BI
Power BI is a powerful ecosystem of business intelligence tools and technologies from Microsoft. But what exactly is business intelligence, anyway? Simply stated, business intelligence is all about leveraging data to make better decisions. This can take many forms and is not necessarily restricted to just business. We use data in our personal lives to make better decisions as well. For example, if we are remodeling a bathroom, we get multiple quotes from different firms. The prices and details in these quotes are pieces of data that allow us to make an informed decision in terms of which company to choose. We may also research these firms online. This is more data that ultimately supports our decision.
In this chapter, we will explore the fundamental concepts of business intelligence, as well as why business intelligence is important to organizations. In addition, we will take a high-level tour of the Power BI ecosystem, licensing, and core tools, such as Power BI Desktop and the Power BI service.
The following topics will be covered in this chapter:
- Exploring key concepts of business intelligence
- Discovering the Power BI ecosystem
- Choosing the right Power BI license
- Introducing Power BI Desktop and the Power BI service
Exploring key concepts of business intelligence
In the context of organizations, business intelligence is about making better decisions for your business. Unlike the example in the introduction, organizations are not generally concerned with bathrooms but rather with what can make their business more effective, efficient, and profitable. The businesses that provided those quotes on bathroom remodeling need to answer questions such as the following:
- How can the business attract new customers?
- How can the business retain more customers?
- Who are the competitors and how do they compare?
- What is driving profitability?
- Where can expenses be diminished?
There are endless questions that businesses need to answer every day, and these businesses need data coupled with business intelligence tools and techniques to answer such questions and make effective operational and strategic decisions.
While business intelligence is a vast subject in and of itself, the key concepts of business intelligence can be broken down into five areas:
- Domain
- Data
- Model
- Analysis
- Visualization
Domain
A domain is simply the context where business intelligence is applied. Most businesses are composed of relatively standard business functions or departments, such as the following:
- Sales
- Marketing
- Manufacturing/production
- Supply chain/operations
- Research and development
- Human resources
- Accounting/finance
Each of these business functions or departments represents a domain within which business intelligence can be used to answer questions that can assist us in making better decisions.
The domain helps in narrowing down the focus regarding which questions can be answered and what decisions need to be made. For example, within the context of sales, a business might want to know which sales personnel are performing better or worse, or which customers are the most profitable. Business intelligence can provide such insights as well as help to determine which activities enable certain sales professionals to outperform others, or why certain customers are more profitable than others. This information can then be used to train and mentor sales personnel who are performing less effectively or to focus sales efforts.
Within the context of marketing, a business can use business intelligence to determine which types of marketing campaigns, such as email, radio, print, TV, and the web, are most effective in attracting new customers. This then informs the business where they should spend their marketing budget.
Within the context of manufacturing, a business can use business intelligence to determine the Mean Time Between Failure (MTBF) for machines that are used in the production of goods. This information can be used by the business to determine
whether preventative maintenance would be beneficial and how often such preventative maintenance should occur.
Clearly, there are endless examples of where business intelligence can make an organization more efficient, effective, and profitable. Deciding on a domain in which to employ business intelligence techniques is a key step in enabling business intelligence undertakings within organizations, since the domain dictates which key questions can be answered, the possible benefits, as well as what data is required in order to answer those questions.
Data
Once a domain has been decided upon, the next step is identifying and acquiring the data that’s pertinent to that domain. This means identifying the sources of relevant data. These sources may be internal or external to an organization and may be structured, unstructured, or semi-structured in nature.
Internal and external data
Internal data is data that is generated within an organization by its business processes and operations. These business processes can generate large volumes of data that is specific to that organization’s operations. This data can take the form of net revenues, sales to customers, new customer acquisitions, employee turnover, units produced, cost of raw materials, and time series or transactional information. This historical and current data is valuable to organizations if they wish to identify patterns and trends, as well as
for forecasting and future planning. Importantly, all the relevant data to a domain and question is almost never housed within a single data source; organizations inevitably have multiple sources of relevant data.
In addition to internal data, business intelligence is most effective when internal data is combined with external data. Crucially, external data is data that is generated outside the boundaries of an organization’s operations. Such external data includes things
such as overall global economic trends, census information, customer demographics, household salaries, and the cost of raw materials. All this data exists irrespective of any single organization.
Each domain and question will have internal and external data that is relevant and irrelevant to answering the question at hand. However, do not be fooled into believing that simply because you have chosen manufacturing/production as the domain, other domains, such as sales and marketing, do not have relevant sources of data. If you are trying to forecast the required production levels, sales data in terms of pipelines can be very relevant. Similarly, external data that points toward overall economic growth may also be extremely relevant, while data such as the cost of raw materials may very well be irrelevant.
Structured, unstructured, and semi-structured data
Structured data is data that conforms to a rather formal specification of tables with rows and columns. Think of a spreadsheet where you might have columns for the transaction ID, customer, units purchased, and price per unit. Each row represents a sales transaction. Structured data sources are the easiest sources for business intelligence tools to consume and analyze. These sources are most often relational databases, which include technologies such as Microsoft SQL Server, Microsoft Access, Azure Table storage, Azure SQL Database, Oracle, MySQL, IBM Db2, Teradata, PostgreSQL, Informix, and Sybase. In addition, this category of data sources includes relational database standards such as Open Database Connectivity (ODBC) and Object Linking and Embedding Database (OLE DB).
Unstructured data is effectively the opposite of structured data. Unstructured data cannot be organized into simple tables with rows and columns. Such data includes things such
as video, audio, images, and text. Text documents, social media posts, and online reviews are also examples of largely unstructured data. Unstructured data sources are the most difficult types of sources for business intelligence tools to consume and analyze. This type of data is either stored as Binary Large Objects (BLOBSs), online files or posts,
or as files in a filesystem, such as the New Technology File System (NTFS) or the
Hadoop Distributed File System (HDFS).
Semi-structured data has a structure but does not conform to the formal definition of structured data, that is, tables with rows and columns. Examples of semi-structured data include tab and delimited text files, XML, other markup languages such as HTML and XSL, JavaScript Object Notation (JSON), and Electronic Data Interchange (EDI).
Semi-structured data sources have a self-defining structure that makes them easier to consume and analyze than unstructured data sources but require more work than true, structured data sources.
Semi-structured data also includes so-called NoSQL databases, which include data stores such as document databases, graph databases, and key-value stores. These databases are specifically designed to store structured and unstructured data. Document databases include Microsoft Azure Cosmos DB, MongoDB, Cloudant (IBM), Couchbase, and MarkLogic. Graph databases include Neo4j and HyperGraphDB. Key-value stores include Basho Technologies’ Riak, Redis, Aerospike, Amazon Web Services’ DynamoDB, Couchbase, DataStax’s Cassandra, and MapR Technologies. Wide-column stores include Cassandra and HBase.
Finally, semi-structured data also includes data access protocols, such as Open Data Protocol (OData) and other Representational State Transfer (REST) Application Programming Interfaces (APIs). These protocols provide interfaces to data sources such as Microsoft SharePoint, Microsoft Exchange, Microsoft Active Directory, and Microsoft Dynamics; social media systems such as Twitter and Facebook; as well as other online systems such as Mailchimp, Salesforce, Smartsheet, Twilio, Google Analytics, and GitHub, to name a few. These data protocols abstract how the data is stored, whether that is
a relational database, NoSQL database, or simply a bunch of files.
Most business intelligence tools, such as Power BI, are optimized for handling structured and semi-structured data. Structured data sources integrate natively with how business intelligence tools are designed. In addition, business intelligence tools are designed to ingest semi-structured data sources and transform them into structured data. Unstructured data is more difficult but not impossible to analyze with business intelligence tools.
In fact, Power BI has some features that are designed to ease the ingestion and analysis of unstructured data sources. However, analyzing such unstructured data has its limitations.
Model
A model, or data model, refers to the way in which one or more data sources are organized to support analysis and visualization. Models are built by transforming and cleansing data, helping to define the types of data within those sources, as well as the definition of data categories for specific data types. Building a model generally involves three elements:
- Organizing
- Transforming and cleansing
- Defining and categorizing
Organizing
Models can be extremely simple, such as a single table with columns and rows. However, business intelligence almost always involves multiple tables of data, and often involves multiple tables of data coming from multiple sources. Thus, the model becomes more complex as the various sources and tables of data must be combined into a cohesive whole. This is done by defining how each of the disparate sources of data relates to one another. As an example, let’s say you have one data source that represents a customer’s name, contact information, and perhaps the size of the business by revenue and/or the number of employees. This information might come from an organization’s Customer Relationship Management (CRM) system. The second source of data might be order information, which includes the customer’s name, units purchased, and the price that was paid. This second source of data comes from the organization’s Enterprise Resource
Planning (ERP) system. These two sources of data can be related to one another based on the unique name or ID of the customer.
Some sources of data have prebuilt models. Th s includes traditional data warehouse technologies for structured data as well as analogous systems for performing analytics over unstructured data. The traditional data warehouse technology is generally built upon the Online Analytical Processing (OLAP) technology and includes systems such as Microsoft Analysis Services, Snowflake, Oracle’s Essbase, AtScale cubes, SAP HANA and
Business Warehouse servers, and Azure Synapse. With respect to unstructured data analysis, technologies such as Apache Spark, Databricks, and Azure Data Lake Storage are used.
Transforming and cleansing
When building a data model, it is often (read: always) necessary to clean and transform the source data. Data is never clean – it must always be massaged for bad data to be removed or resolved. For example, when dealing with customer data from a CRM system, it is not uncommon to have the same customer entered with multiple spellings. The format of data in spreadsheets may make data entry easy for humans but can be unsuitable for business intelligence purposes. In addition, data may have errors, missing data, inconsistent formatting, or even have something as seemingly simple as trailing spaces.
These types of situations can cause problems when performing business intelligence analysis. Luckily, business intelligence tools such as Power BI provide mechanisms for cleansing and reshaping the data to support analysis. This might involve replacing
or removing errors in the data, pivoting, unpivoting, or transposing rows and columns, removing trailing spaces, or other types of transformation operations.
Transforming and cleansing technologies are often referred to as Extract, Transform, Load (ETL) tools and include products such as Microsoft’s SQL Server Integration Services (SSIS), Azure Data Factory, Alteryx, Informatica, Dell Boomi, Salesforce’s MuleSoft, Skyvia, IBM’s InfoSphere Information Server, Oracle Data Integrator, Talend, Pentaho Data Integration, SAS’s Data Integration Studio, Sybase ETL, and QlikView Expressor.
Defining and categorizing
Data models also formally define the types of data within each table. Data types generally include formats such as text, decimal number, whole number, percentage, date, time, date and time, duration, true/false, and binary. The definition of these data types is important as it defines what kind of analysis can be performed on the data. For example, it does
not make sense to create a sum or average of text data types; instead, you would use aggregations such as count, first, or last.
Finally, data models also define the data category of data types. While a data type such as a postal code might be numeric or text, it is important for the model to define that the numeric data type represents a postal code. This further defines the type of analysis that can be performed upon this data, such as plotting the data on a map. Similarly, it might be important for the data model to define that a text data type represents a web or image
Uniform Resource Locator (URL). Typical data categories include such things as address, city, state, province, continent, country, region, place, county, longitude, latitude, postal code, web URL, image URL, and barcode.
Analysis
Once a domain has been selected and data sources have been combined into a model, the next step is to perform an analysis of the data. This is a key process within business
intelligence as this is when you attempt to answer questions that are relevant to the business using internal and external data. Simply having data about sales is not immediately useful to a business. For example, to predict future sales revenue, it is important that such data is aggregated and analyzed. This analysis can determine the average sales for a product, the frequency of purchases, and which customers purchase more frequently than others. Such information allows better decision-making by an organization.
Data analysis can take many forms, such as grouping data, creating simple aggregations such as sums, counts, and averages, as well as creating more complex calculations, identifying trends, correlations, and forecasting. Many times, organizations have, or wish to have, Key Performance Indicators (KPIs), which are tracked by the business to help determine the organization’s health or performance. KPIs might include such things as employee retention rate, net promoter score, new customer acquisitions per month, gross margin, and Earnings Before Interest, Tax, Depreciation, and Amortization (EBITDA). Such KPIs generally require that the data is aggregated, has calculations performed on it, or both. These aggregations and calculations are called metrics or measures and are used to identify trends or patterns that can inform business decision-making. In some cases, advanced analysis tools such as programming languages, machine learning and artificial intelligence, data mining, streaming analytics, and unstructured analytics are necessary to gain the proper insights.
There are numerous programming languages that have either been specifically designed from the ground up for data analytics or have developed robust data analytics packages or extensions. Two of the most popular languages in this space include R and Python.
Other popular languages include SQL, Multidimensional Expressions (MDX), Julia, SAS, MATLAB, Scala, and F#.
There is also a wide variety of machine learning and data mining tools and platforms for performing predictive analytics around data classification, regression, anomaly
detection, clustering, and decision-making. Such systems include TensorFlow, Microsoft’s Azure Machine Learning, DataRobot, Alteryx Analytics Hub, H2O.ai, KNIME, Splunk, RapidMiner, and Prevedere.
Streaming analytics becomes important when dealing with Internet of Things (IoT) data. In these situations, tools such as Striim, StreamAnalytix, TIBCO Event Processing, Apache Storm, Azure Stream Analytics, and Oracle Stream Analytics are used.
When dealing with unstructured data, tools such as Pig and Hive are popular, as well as tools such as Apache Spark and Azure Cognitive Services for vision, speech, and sentiment analysis.
Of course, any discussion around data analytics tools would be incomplete without including Microsoft Excel. Spreadsheets have long been the go-to analytics tool for business users, and the most popular spreadsheet today is Microsoft Excel. However, other spreadsheet programs, such as Google Sheets, Smartsheet, Apple Numbers, Zoho Sheet, and LibreOffice Calc, also exist.
Visualization
The final key concept in business intelligence is visualization or the actual presentation of the analysis being performed. Humans are visually oriented and thus it is advantageous to view the results of the analysis in the form of charts, reports, and dashboards. This may take the form of tables, matrices, pie charts, bar graphs, and other visual displays that help provide context and meaning to the analysis. In the same way that a picture is worth a thousand words, visualizations allow thousands, millions, or even trillions of individual data points to be presented in a concise manner that is easily consumed and
understandable. Visualization allows the analyst or report author to let the data tell a story. This story answers the questions that are originally posed by the business and thus delivers the insights that allow organizations to make better decisions.
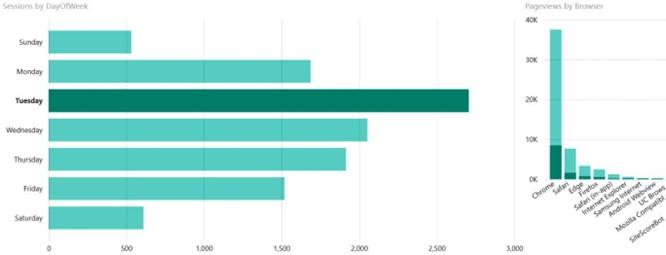
Individual charts or visualizations typically display aggregations, KPIs, and/or other calculations of underlying data that’s been summarized by some form of grouping. These charts are designed to present a specific facet or metric of the data within a specific context. For example, one chart may display the number of web sessions by the day of the week, while another chart may display the number of page views by browser.
Business intelligence tools allow multiple individual tables and charts to be combined on a single page or report. Modern business intelligence tools such as Power BI support interactivity between individual visualizations to further aid the discovery and analysis process. This interactivity allows the report consumer to click on portions of individual visualizations, such as bar charts, maps, and tables, in order to drill down, highlight,
or filter the information presented or determine the influence of a particular portion of a chart on the rest of the visualizations in a report. This goes beyond typical legacy visualization tools such as SQL Server Reporting Services (SSRS) or Crystal Reports,
which only provide minimal user interactivity when it comes to choosing from predefined filters. For example, given the two charts we referenced previously, the report consumer can click on a particular day of the week in the first report to display the page visit breakdown per browser for the chosen day of the week in the second chart:
Figure 1.1 – Two bar charts: (L) Sessions by DayOfWeek; (R) Pageviews by Browser
Finally, dashboards provide easy-to-understand visualizations of KPIs that are important to an organization. For example, the CEO of a corporation may wish to see only certain information from sales, marketing, operations, and human resources. Each of these departments may have its own detailed reports, but the CEO only wishes to track one
or two of the individual visualizations within each of those reports. Dashboards enable this functionality.
Visualization software includes venerable tools such as SSRS and Crystal Reports, as well as software such as Birst, Domo, MicroStrategy, Qlik Sense, Tableau CRM, SAS Visual Analytics, Sisense, Tableau, ThoughtSpot, and TIBCO Spotfire.
Now that we have examined the key concepts and overarching themes of business intelligence, it is time to delve a layer deeper and discover the business intelligence- enabling technologies that comprise the Power BI ecosystem.